2024年4月14日
WindowsでAIプログラミング
MakeItTalk:実装方法
目次
はじめに
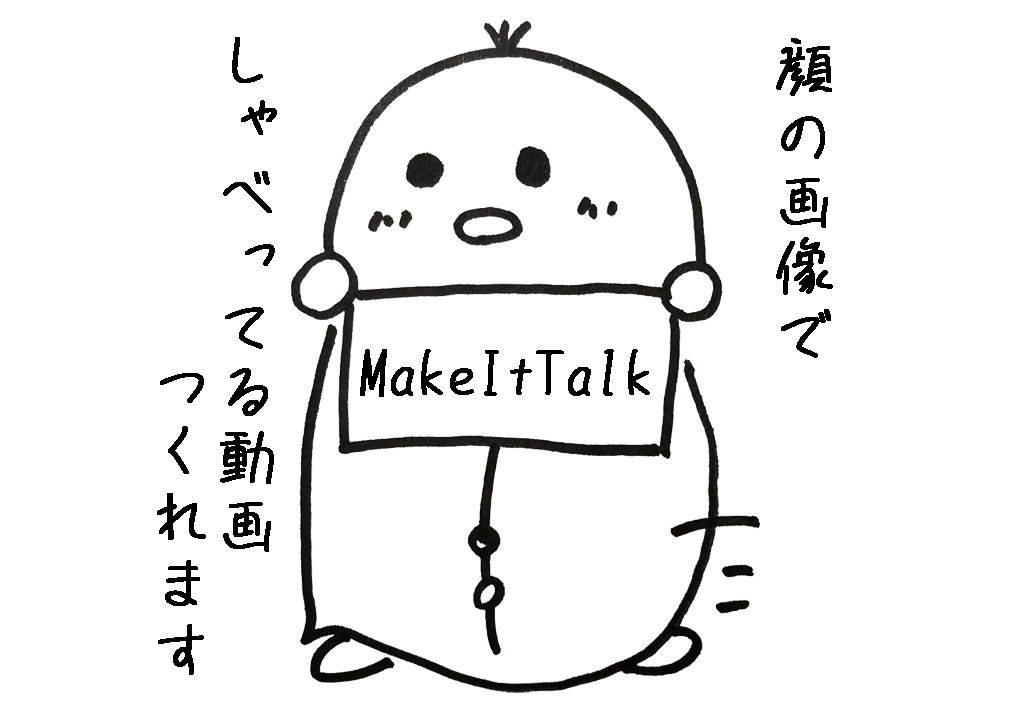
『MakeItTalk』は、顔の画像に、任意の音声ファイルを合成し、
しゃべっている風の動画を作成できます。
今回は、『WSL』を使って実装しました。
実行PC環境
Windows10 pro (Windows Insier Program)
マウスコンピューター製G-Tune E5-144
CPU:インテル(R) Core(TM) i7-10875H プロセッサー
メモリ:32GB メモリ
SSD (M.2):512GB NVMe SSD
グラフィックス:NVIDIA GeForce RTX2060 / 6GB
方法
WSLの環境設定
任意のフォルダで『WLS』を起動(今回は、Ubuntu20.04にて行っています)
※WSLの初期設定は、こちらを参考にしてください。
WSL:CUDA10.1を設定(Ubuntu20.04)
WSL:pyenvの実装(Ubuntu20.04、Ubuntu18.04)
必要なモジュールのインストール
(こちらは、すでに設定済みなど、設定環境により違うので適宜実行してください。)
|
1 2 3 4 5 6 7 8 |
sudo apt-get install ffmpeg sudo apt install openssl libssl-dev sudo dpkg --add-architecture i386 wget -nc https://dl.winehq.org/wine-builds/winehq.key sudo apt-key add winehq.key sudo apt-add-repository 'deb https://dl.winehq.org/wine-builds/ubuntu/ xenial main' sudo apt update sudo apt install --install-recommends winehq-stable |
Gitで設定
|
1 |
git clone https://github.com/yzhou359/MakeItTalk |
カレントディレクトリの移動
|
1 |
cd MakeItTalk |
pyenvの設定
バージョン3.6.8をローカル設定します
|
1 |
pyenv local 3.6.8 |
仮想環境の設定
仮想環境の作成
|
1 |
python -m venv venv-wsl-20.04 |
仮想環境を実行
|
1 |
source venv-wsl-20.04/bin/activate |
モジュールのインストール
|
1 2 3 4 5 |
python -m pip install pip -U python -m pip install setuptools -U python -m pip install -r requirements.txt python -m pip install torch==1.5.0+cu101 torchvision==0.6.0+cu101 -f https://download.pytorch.org/whl/torch_stable.html python -m pip install tensorboardX |
学習済みモデルのダウンロード
pthファイル
下記のファイルをURLよりダウンロードします。
ckpt_autovc.pth (Voice Conversion)
https://drive.google.com/file/d/1ZiwPp_h62LtjU0DwpelLUoodKPR85K7x/view
ckpt_content_branch.pth (Speech Content Module)
https://drive.google.com/file/d/1r3bfEvTVl6pCNw5xwUhEglwDHjWtAqQp/view
ckpt_speaker_branch.pth (Speaker-aware Module)
https://drive.google.com/file/d/1rV0jkyDqPW-aDJcj7xSO6Zt1zSXqn1mu/view
ckpt_116_i2i_comb.pth (Image2Image Translation Module)
https://drive.google.com/u/0/uc?id=1i2LJXKp-yWKIEEgJ7C6cE3_2NirfY_0a&export=download
これら4つのファイルを既存フォルダ『examples』に、新しく『ckpt』というフォルダを作り保存します。
pickleファイル
下記のファイルをURLよりダウンロードします。
(Animate You Portraits! pre-trained embedding)
https://drive.google.com/file/d/18-0CYl5E6ungS3H4rRSHjfYvvm-WwjTI/view
実行コマンド
|
1 |
python main_end2end.py --jpg anne.jpg |
デフォルトで、色々な画像が『example』に入っていますので、
コマンドのjpg名を変更して同じように実行できます。
結果
実行コマンドの結果、『example』フォルダに、下記のファイルが生成されます。
コマンドで指定した画像から、『example』フォルダにある『.wav』ファイル全部の動画が作成されます。
『anne_pred_fls_M6_04_16k_audio_embed.mp4』
『M6_04_16k_av.mp4』
さいごに
できればWSLを使わず実装してみたいでふ、
検討でふね(‘ω’)ノ
補足
実行コマンドの際、なんらかのエラーで途中で終わると、
『example』フォルダに『tmp.wav』というファイルが残ることがあります。
このファイルが存在すると再度実行する際にエラーになるため、
都度消してください。
化学系で博士号を取得したが、
あるとき、これからの時代はプログラミング!、と目覚める。
pythonを用いてデータ解析や機械学習に没頭。
最近は、Pytorchで作ったONNXモデルを、Nuxt3にのせたWebサービスの開発、
ChatGPT や Stable Diffusion に没頭中☆('ω')☆
SNSでフォローする
関連記事
